

The Cornell psychologist Daryl Bem published a study in 2011 which showed he had found evidence of people being able to see the future. This was the last straw. The problem with the way psychology went about statistics was always going to throw up something silly and now it had. Wagenmaker et. al. (2011) was moved to say “[…] the field of psychology currently uses methodological and statistical strategies that are too weak, too malleable, and offer too many opportunities for researchers to befuddle themselves and their peers.”
It is not an exaggeration to say that psychology was in crisis. At least the quantitative researchers were. Qualitative psychologists, often derided by their number-crunching collegues, no doubt sniggered into their sleeves.
You may be wondering why it was assumed the results were wrong. Perhaps people really can see into the future! I am going to have to back peddle a little to explain why they can’t, at least not according to the study in question.
You see, psychology depended for decades on something called null hypothesis significance testing (NHST). What psychologists want to do is know what every single person in a given population would do under certain circumstances. Obviously, they can’t test everyone. So what they do is test some of them and infer from that limited number an estimate of the population. To do that they put their numbers through statistical tests which tell them how likely it would be to find the effect they did if no such effect really existed. That is, if there is, for instance, no difference between men and women in reaction times what is the chance of finding one through some fluke? Fisher, way back in the 1920s, decided that if that chance was only 5% or less then you could report a significant result. But why 5%, students ask, quite reasonably. And how do you know your results don’t fall into the 5% fluke range? The answer to the first question is that is the side of the bed Fisher got out of that morning; the answer to the second question is, you don’t.
If I were to tell you that at the last election there was a significant difference between the red party and the blue party you’d argue that didn’t really tell you anything. That, though, is what NHST has been telling psychologists for decades. Nothing more than that. Fisher never really intended for his statistical method to be used as a benchmark by which studies were published. To him, it was nothing more than a useful tool which told you there was something worth looking at more deeply. However, psychology didn’t listen and such studies were indeed published and have been ever since, each claiming that p<.05 (where ‘p’ means significance).
Another problem with 'p' is that it tells you how likely your data are if the null hypothesis is true. That is, how likely it was to have found a difference by chance if no difference really exists. The trouble is, the null hypothesis can never be true (you can't say for sure something doesn't exist; you can only say you haven't found it yet).
Apart from the fact ‘p’ doesn’t tell you what as a psychologist you want to know, like where is the effect and how big it is, it is alarmingly too easy to manipulate. All psychologists know that if you collect 30 participants and find no significant difference between groups then just keep adding participants until you do. It doesn’t mean there really is something interesting going on; it’s just a peculiarity of NHST that if you keep increasing your sample size you will eventually find significance. This is called p hacking and it is cheating. That brings us back to Bem (2011).
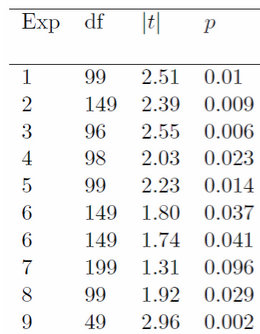
Have a look here at Bem’s results. There are 9 experiments testing the ability to see the future. ‘df’ stands for degrees of freedom and is the number of participants in that experiment. ‘t’ stands for test statistic and ‘p’ is significance. In each experiment except experiment 7 (p>0.05) a significant result was found. Look at the participant numbers, though. They range from 49 to 199. This ought to make any reviewer suspicious. It looks like he kept adding participants until he found significance. He got all the way to 199 in the one that showed nothing before giving up.
It took a study suggesting that people can see into the future to confront this properly but NHST was how almost all studies were done till then. They still are most of them.
What you can do is something called a Power Analysis. You tell a programme what sort of design your experiment is, how powerful you want it to be and what you want to set 'p' as and it tells you how many participants you need. You shouldn't go over that number. The trouble is, if a psychological experiment uses a Power Analysis it very rarely says so in my experience. Not only that, if you see in the method section of a published study a large sample you are more likely to be impressed than immediately suspicious.
What you can do is something called a Power Analysis. You tell a programme what sort of design your experiment is, how powerful you want it to be and what you want to set 'p' as and it tells you how many participants you need. You shouldn't go over that number. The trouble is, if a psychological experiment uses a Power Analysis it very rarely says so in my experience. Not only that, if you see in the method section of a published study a large sample you are more likely to be impressed than immediately suspicious.
Fortunately, there are better ways of analysing data and psychology is moving toward adopting them. Remember how I told you there was a significant difference between the red party and the blue party at the last election? What if now I were to tell you the red party had 60% of the vote and that the margin of error was 7%, would that be better? At least now you have a lot more information to go on. That’s what psychologists are doing now with effect sizes. There is no excuse now for looking at a published paper in a psychology journal and not seeing effect sizes displayed alongside ‘p’ allowing you to see what the effect actually was and how big it was too. The great thing about effect sizes is that they stay the same no matter how many participants you throw at them, unlike ‘p’ values.
Then there are confidence intervals (CI). A CI tells you what the mean score of your sample was but also gives an estimate of how accurate a representation of the population mean it is. This is what they look like:

What we really want to know is how far from the true mean each of those little black squares are. We can’t test everyone but mathematicians have worked out an ingenious way of doing that from just a single sample. This amount of variability in the estimation of the population mean is called the standard error (SE). Don’t ask me how they know this as I am not a statistician despite the amount of it psychologists need to learn, but they know that if you draw a line (as above) 2 SEs either side of the sample mean then 95% of the time, the true and unknowable population mean will fall somewhere within them. The shorter those lines the better.
So now we’re getting to see much more deeply into our results than we could from a simple ‘p’ value. There is more, though. Bayesian statistics have been around a long time but computing power needed to catch up. They are a little controversial as you have to factor in an arbitrary value. What you do is, you work out your prior belief (what you already believe about what your study will show). Next, you run the experiment and input the data you came up with. Then you’re told how you should update your prior belief given the data you now have.
That may sound an odd way to go about it. However, as Carl Sagan said, 'Extraordinary claims require extraordinary proof.' Now we have a statistical model which challenges extraordinary claims to be supported by extraordinary proof. How would this have affected Bem and his experiment on seeing into the future? Since this is an extraordinary claim that is not supported by any evidence so far your prior belief ought to be quite strongly biased against it. Bem’s results, therefore, would not have been powerful enough to update your belief significantly.
Below you can see this working with Bayesian statistics and our ability to see the future. In the first example, we have someone with no prior belief at the top (prior). Then we get the results (likelihood). Then we get the updated belief (posterior). Because the experimenter had no prior belief, the data was able to update that belief dramatically even though it was weak.

Now look below at someone who has a strong prior belief that people cannot see into the future; someone who believes extraordinary claims require extraordinary proof. His prior belief is around zero. The data is weak so his updated belief barely shifts at all.

The whole prior belief thing does bother people as it is arbitrary, but it is based on prior research. If there is none, the prior is usually set conservatively. However, even a conservative prior still doesn’t help Bem and his findings. Indeed, if you apply Bayes to Bem's findings, only one of his experiments shows results anywhere near interesting and even then not very (quite a come down from 8 out of 9).
Some psychology publications are not accepting p values at all now. Some say that within 10 years p values will be dead, though apparently that was said 10 years ago too (which just goes to show people really can’t see into the future!) Some universities are teaching the new statistics and encourging students to evaluate studies based on this more modern understanding. They are on their way out, though. At the very least, what they can and can’t tell us is better appreciated.
Refs.
Bem, D. J. (2011). Feeling the future: experimental evidence for anomalous retroactive influences on cognition and affect. Journal of personality and social psychology, 100(3), 407.
Bem, D. J. (2011). Feeling the future: experimental evidence for anomalous retroactive influences on cognition and affect. Journal of personality and social psychology, 100(3), 407.
Wagenmakers, E. J., Wetzels, R., Borsboom, D., & Van Der Maas, H. L. (2011). Why psychologists must change the way they analyze their data: the case of psi: comment on Bem (2011).